Method Overview
VolumeDP first lifts image features into a 3D Volumetric Representation through Cross-Attention. A Spatial Token Generation module then learns to select task-relevant voxels, such as regions around the end-effector and manipulated objects, and compresses them into compact spatial tokens. Finally, a Multi-Token Decoder conditions on the full set of spatial, language, and proprioceptive tokens to generate coherent action sequences.
Real-World Experiment
The real-world experiments are conducted on Galaxea R1 Lite. The robot contains two 6-DoF arms and 1-DoF grippers. Perception is provided by an RGB head camera and an RGB wrist camera. Our benchmarks contain the following four tasks: placing bowl, microwave operation, door opening, and nut onto screw. Compared with Diffusion Policy, VolumeDP improves the average success rate from 57.5% to 76.3%.
Placing bowl
Microwave operation
Door opening
Nut onto screw
Performance on Simulation Environments
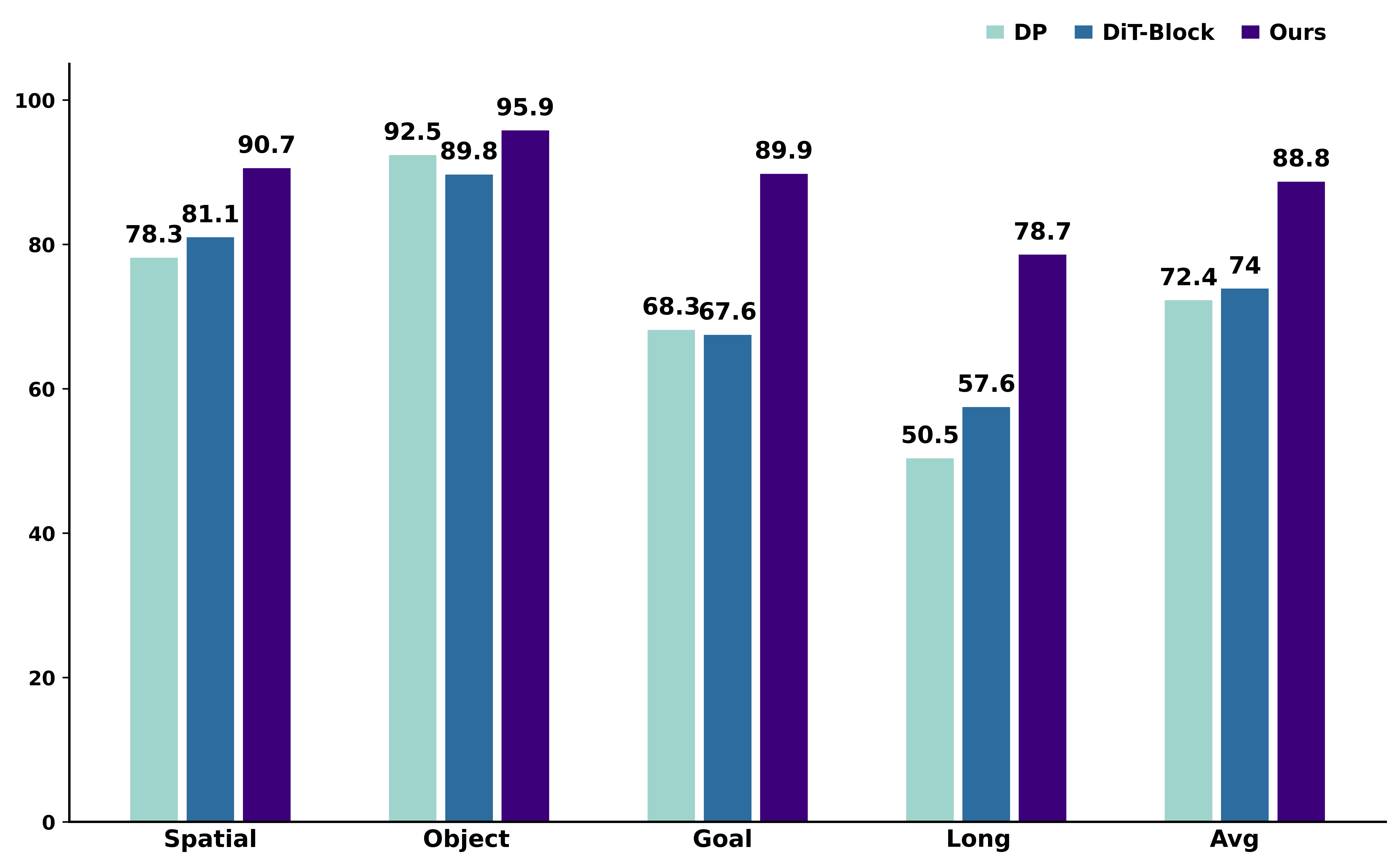
LIBERO
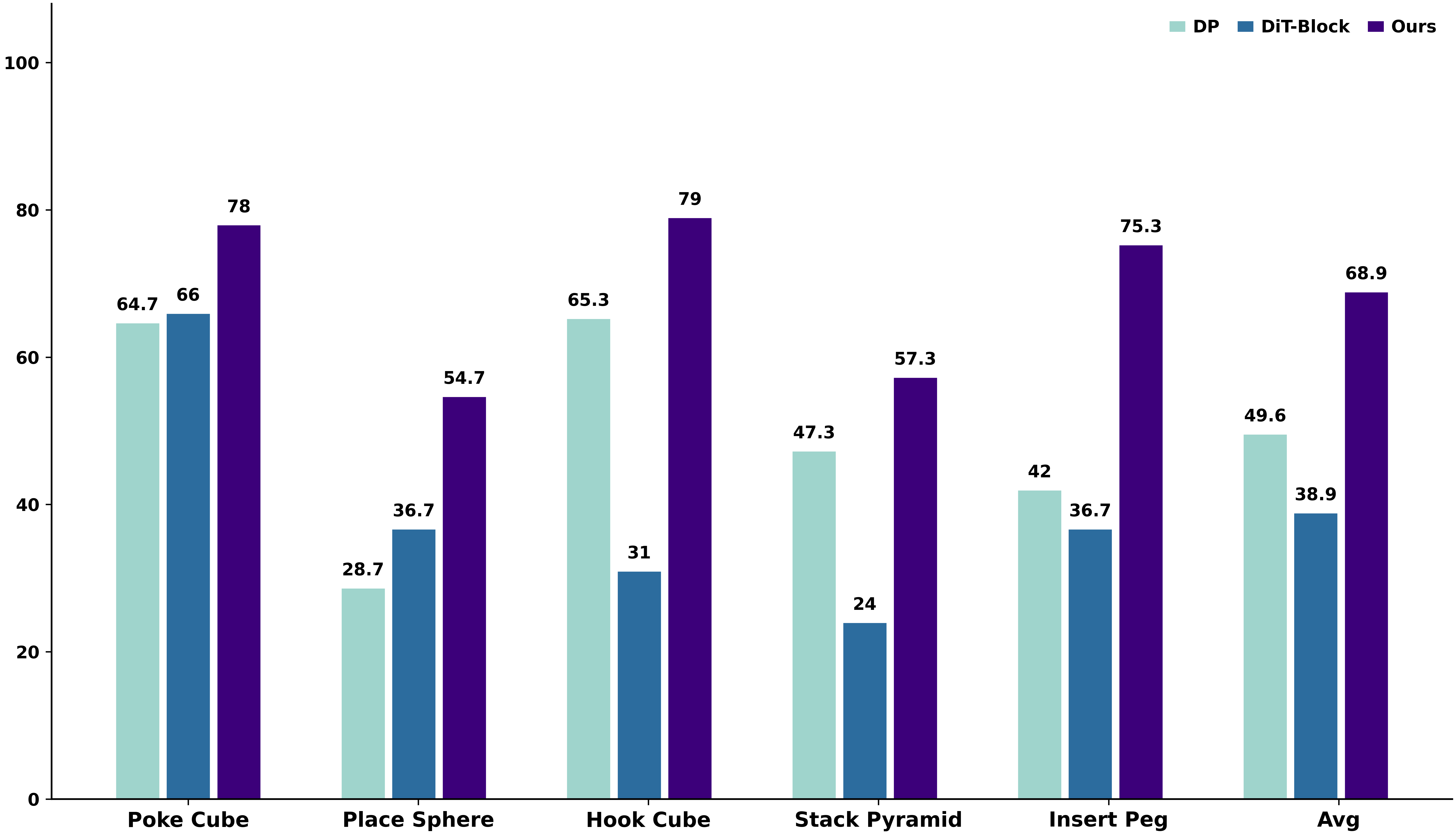
ManiSkill
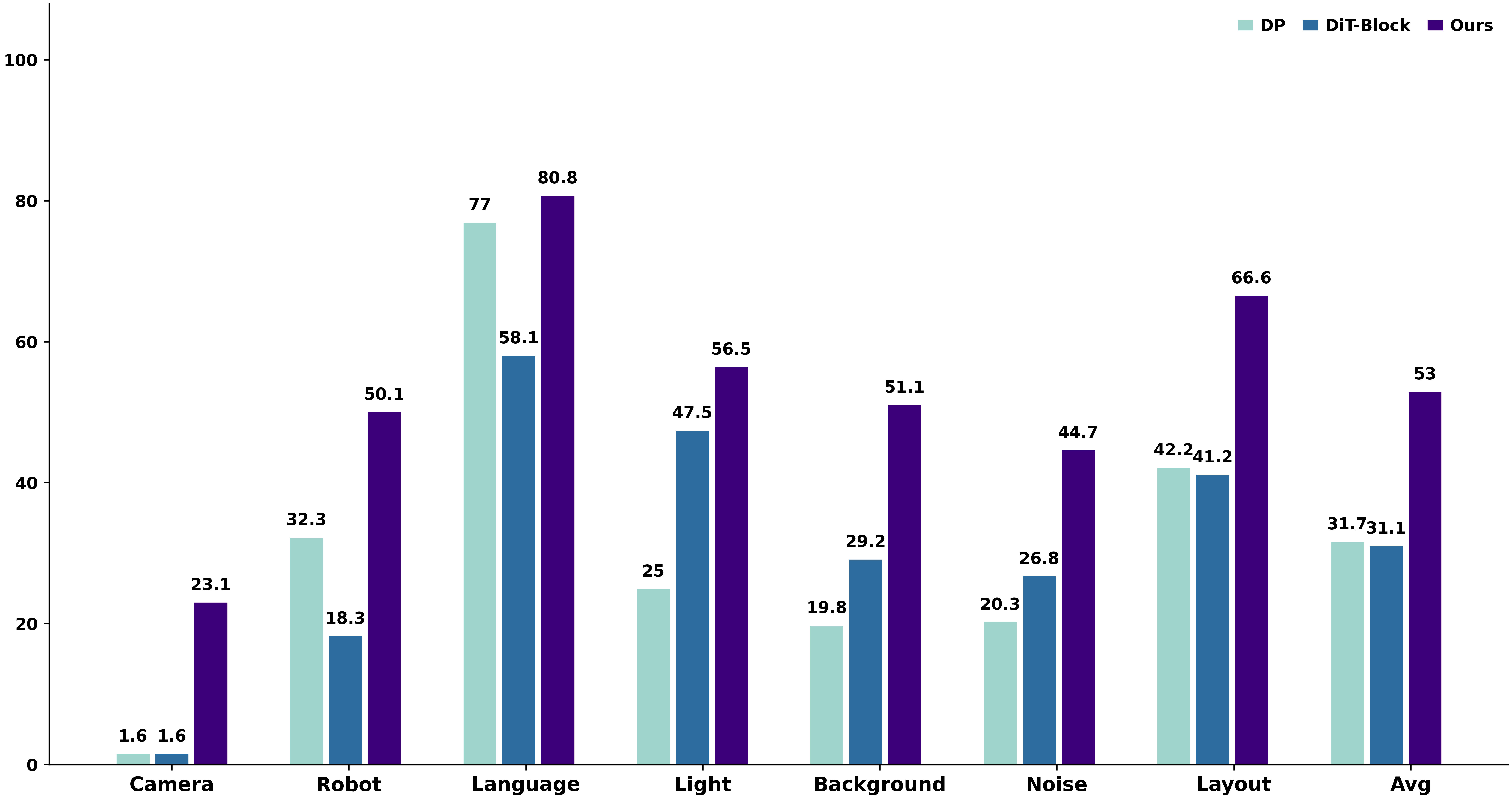
LIBERO-Plus
The Spatial Token Generation module is designed to suppress task-irrelevant information and retain action-critical cues in volumetric representation. Qualitatively, the video below shows that the learned weights concentrate on the end effector and the manipulated object, and even localize the intended grasp contact region, indicating task-relevant spatial focus.
BibTeX
@article{zhou2026volumedp,
title={VolumeDP: Modeling Volumetric Representation for Manipulation Policy Learning},
author={Zhou, Tianxing and Xue, Feiyang and Ye, Zhangchen and Yuan, Tianyuan and Zhao, Hang and Jiang, Tao},
journal={arXiv preprint arXiv:2603.17720},
year={2026}
}